AI - Perceptron
The perceptron is one of the simplest types of artificial neural networks and is often used as an introduction to the basics of machine learning and neural networks. It was originally developed in the 1950s by Frank Rosenblatt.

Frank Rosenblatt (July 11, 1928 – July 11, 1971) was an American psychologist notable in the field of artificial intelligence. He is sometimes called the father of deep learning for his pioneering work on artificial neural networks.
Structure
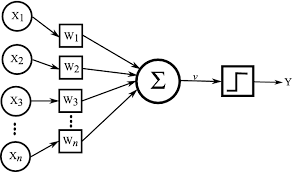
A perceptron is a single-layer neural network, consisting of input nodes (features), weights, a bias term, and an output. Each input feature has an associated weight, which indicates its importance. The perceptron takes these weighted inputs, adds a bias term, and processes the result through an activation function (typically a step function) to produce the output.
Mathematical Model
- The output of the perceptron is calculated by: \(\text{output} = f \left( \sum_{i=1}^{n} w_i x_i + b \right)\)
where \(x_i\) represents the input features, \(w_i\) are the weights, \(b\) is the bias, and \(f\) is the activation function (often a binary step function).
If the output of \(f\) meets a threshold (e.g., greater than 0), it outputs one class; otherwise, it outputs the other class.
Step Function
The step function is a simple activation function used in early neural networks like the perceptron. It determines whether a neuron “fires” based on the input it receives. The step function outputs a binary result, typically 0 or 1, depending on whether the input is above or below a certain threshold.
\[f(x) = \begin{cases} 1 & \text{if } x \geq 0 \\ 0 & \text{if } x < 0 \end{cases}\]If the input \(x\) is greater than or equal to 0, the output is 1. If the input \(x\) is less than 0, the output is 0.
Training
The perceptron uses a supervised learning algorithm. The goal is to adjust weights so that the perceptron correctly classifies the training data. For each data point, the perceptron checks if the predicted output matches the actual label. If it doesn’t, it updates the weights and bias:
\[w_i = w_i + \eta (y - \hat{y}) x_i\]where \(\eta\) is the learning rate, \(y\) is the actual label, and \(\hat{y}\) is the predicted label.
Supervised Learning
Supervised learning is a type of machine learning where a model is trained on a labeled dataset, meaning each input data point is paired with the correct output. The model learns to map inputs to outputs by minimizing errors between its predictions and the actual labels, adjusting its parameters to improve accuracy over time. Once trained, the model can make predictions on new, unseen data based on the patterns it learned from the labeled examples.